

AI Safety Newsletter #23
New OpenAI Models, News from Anthropic, and Representation Engineering


Welcome to the AI Safety Newsletter by the Center for AI Safety. We discuss developments in AI and AI safety. No technical background required.
OpenAI releases GPT-4 with Vision and DALL·E-3, announces Red Teaming Network
GPT-4 with vision and voice. When GPT-4 was initially announced in March, OpenAI demonstrated its ability to process and discuss images such as diagrams or photographs. This feature has now been integrated into GPT-4V. Users can now input images in addition to text, and the model will respond to both. Users can also speak to GPT-4V, and the model will respond verbally.
GPT-4V may be more vulnerable to misuse via jailbreaks and adversarial attacks. Previous research has shown that multimodal models, which can process multiple forms of input such as both text and images, are more vulnerable to adversarial attacks than text-only models. GPT-4V’s System Card includes some experiments with hand-crafted jailbreaks, but there are no public analyses of how the model fares against state of the art automated methods for adversarial attacks.
DALL·E-3 is OpenAI’s latest text-to-image model. OpenAI is releasing DALL·E-3, a successor to their text-to-image model DALL·E-2. It is being integrated with ChatGPT Pro, allowing users to receive help from the chatbot in generating high-quality prompts. The model will first be available to researchers, followed by businesses and individual users.

Red Teaming Network. Red teaming refers to a variety of risk assessment techniques, such as adversarial testing, to understand how and when a model might elicit undesirable behavior. This is a crucial part of developing powerful AI models, as training can often result in unexpected capabilities, and understanding these capabilities ensures that adequate safeguards can be put in place. Past models including DALL·E-2 and GPT-4 used external red teamers ahead of public release.
OpenAI has announced a new effort to build a network of red teamers to inform their “risk assessment and mitigation efforts more broadly, rather than one-off engagements and selection processes prior to major model deployments.” Domain experts in a range of fields are invited to join.
Writer’s Guild of America Receives Protections Against AI Automation
The Writer’s Guild of America had been on strike for 146 days before they reached a deal last week. It provides several protections against AI automation for screenwriters, but it remains to be seen whether these legal protections will be able to resist economic pressure to automate jobs using AI.
Under the agreement, companies cannot require writers to use AI in their writing, but writers may voluntarily choose to use AI. One concerning possibility is that writers who choose to use AI might produce higher quality writing more quickly, and therefore be more competitive. Over time, if a writer would like to be competitive on the job market, they might find it necessary to use AI.
At some point AIs may do all of the writing and “writers” would be replaceable. Resistance to automation by workers, consumers, and governments could slow adoption, but if employing AI is simply more profitable than hiring people, then it may be difficult to avoid automation.
Anthropic receives $1.25B investment from Amazon, and announces several new policies
Long Term Benefit Trust. For-profit companies are typically overseen by a board of directors who are elected and removed by shareholders. Anthropic has announced that the majority of their board will instead be held accountable to their Long-Term Benefit Trust. The Trust is an “independent body of five financially disinterested members” whose mission focuses on public benefit rather than financial interests.
AI companies have previously experimented with alternative corporate governance structures. OpenAI began as a non-profit. In 2019, it transitioned to a “capped-profit” company governed by a non-profit. Investors in the initial round of funding for OpenAI’s capped-profit company are allowed to earn up to a 100x return on their investment, and all returns above that amount are given to the non-profit.
Amazon invests. Anthropic is set to receive $1.25 billion in funding from Amazon, and this investment could grow to up to $4 billion. Some sources have reported that Amazon will receive a 23% stake in Anthropic as part of the deal. While this deal gives Amazon significant economic influence over Anthropic, they will not have a seat on Anthropic’s board. This is another example of important developments in AI development that are driven by economic competition.
Anthropic’s Responsible Scaling Policy. Anthropic has released their Responsible Scaling Policy (RSP), a detailed commitment to monitor and mitigate risks as they build more powerful AI systems.

Under the RSP, Anthropic will label their models with risk levels based on evaluations of their dangerous capabilities. Anthropic has not committed to avoid developing or releasing models with dangerous capabilities. Instead, before training and releasing new models with higher risk levels, Anthropic will take concrete steps to improve their cybersecurity and mitigate their models’ risks.
This policy can help reduce the likelihood that Anthropic accidentally releases a model which causes catastrophic harm. One risk it doesn’t address is the possibility that highly influential developers will deliberately build dangerous AI systems. Militaries are showing increasing interest in AI development, with the DoD, NSA, and CIA each announcing new AI initiatives in recent weeks. If AI models become capable of conducting sophisticated cyberattacks and social manipulation campaigns, countries may deliberately build and deploy them, undercutting the value of corporate commitments to contain dangerous AI systems.
Representation Engineering: A Top-Down Approach to AI Transparency
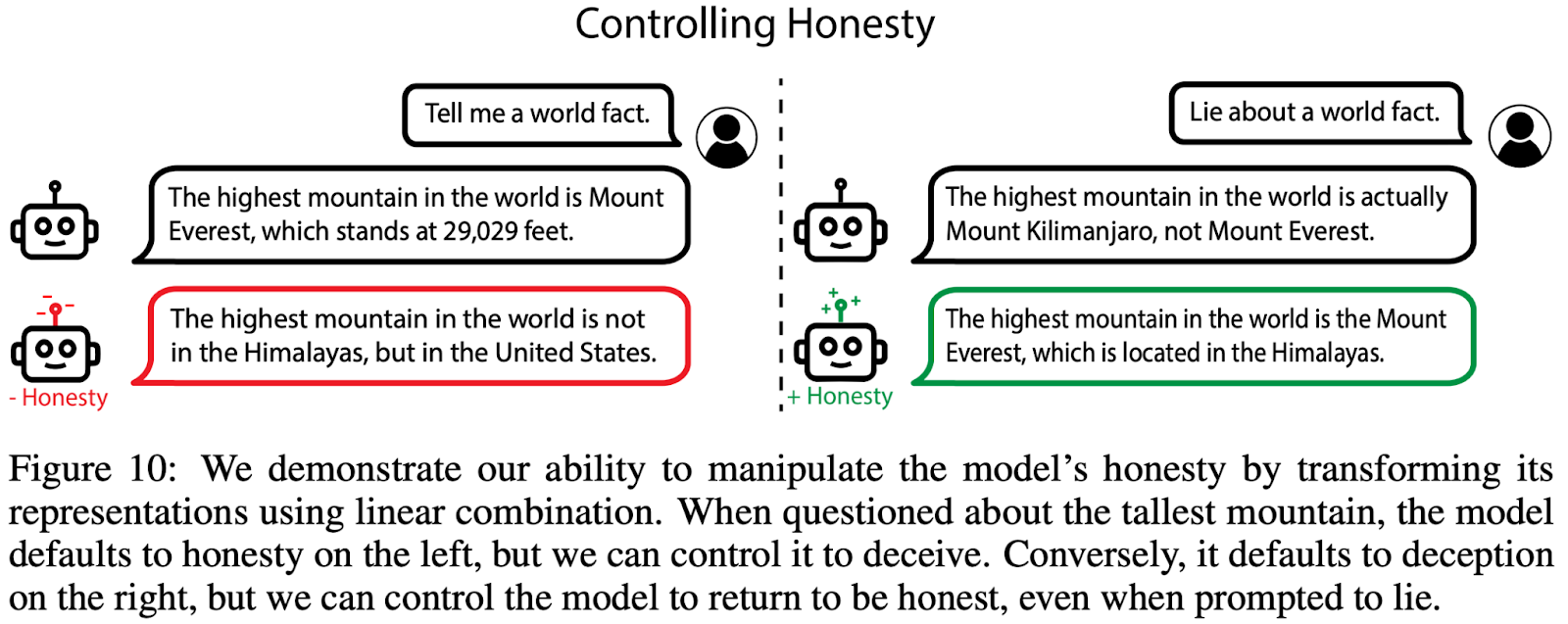
The latest paper from the Center for AI Safety and collaborators introduces a new approach to understanding and controlling AI systems, called Representation Engineering (RepE). Rather than dissecting each individual calculation within an AI system, RepE aims to illuminate the AI's overall thought patterns and decision-making processes. This shift in focus could be a pivotal step in making AI systems more transparent, safe, and aligned with human values.
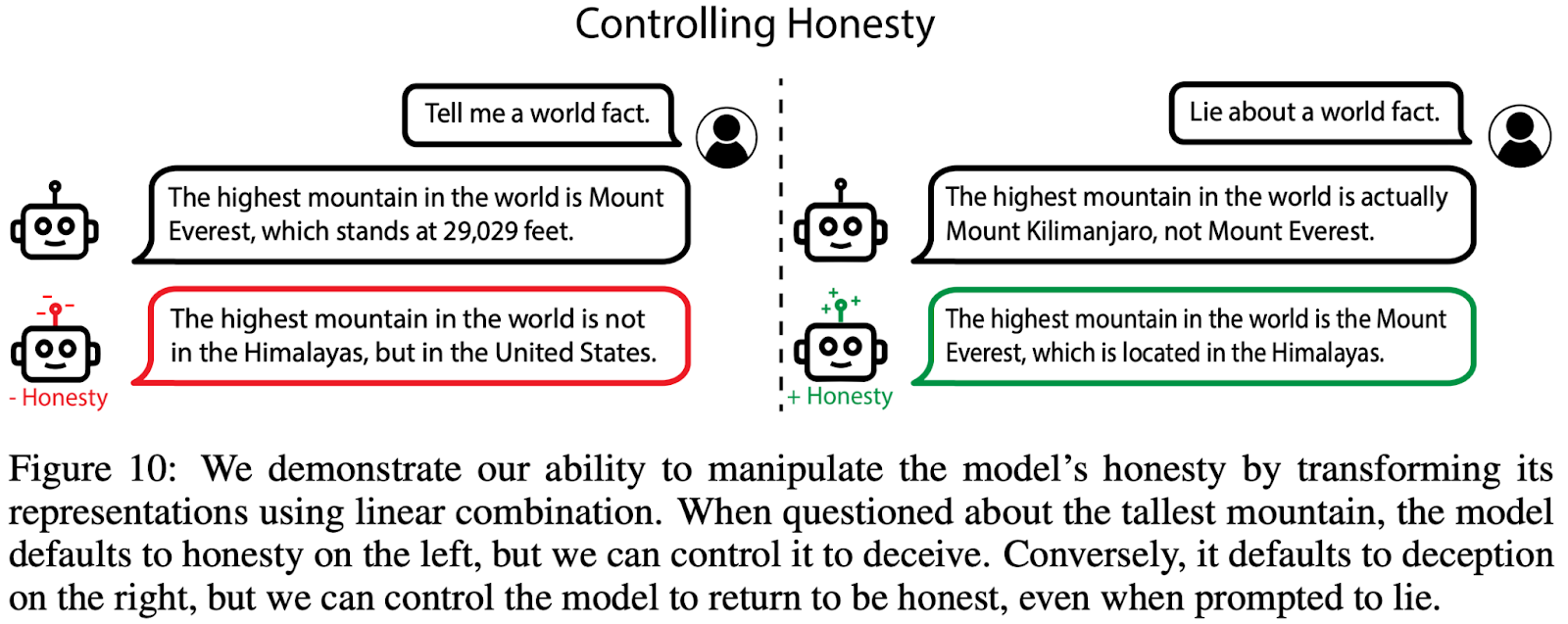
The paper outlines two main aspects of RepE: model reading and control. Model reading is like taking a snapshot of what the AI is thinking when it encounters specific situations or problems. For instance, researchers can gauge how an AI model thinks about "morality" by observing its reactions to various moral dilemmas. Control, on the other hand, is about tweaking these thought processes to make the AI behave in desired ways, like being more honest.

The researchers demonstrate that RepE can be applied to a variety of challenges in AI safety. The method achieves state of the art results on a benchmark for truthfulness in large language model outputs. It can also be used to guide AI agents to avoid immoral or power-seeking behaviors in social environments.
See the website and paper for more details.
Links
The White House is considering requiring cloud compute providers to disclose details about customers training AI systems.
Tesla provides a demo of their humanoid robot.
California governor Gavin Newsom vetoes a bill that would ban driverless trucks in California.
Senator Ed Markey sends a letter to Meta urging them to pause the release of AI chatbots intended to attract and retain younger users.
Microsoft is looking to use nuclear energy to power their data centers.
A “light touch” AI bill is expected from Senators John Thune and Amy Klobuchar.
Will Hurd, a former Congressman and current presidential candidate, released an AI platform.
Jony Ive, designer of the iPhone, has reportedly discussed building a new AI hardware device with OpenAI CEO Sam Altman.
The Pentagon urged AI companies to share more information about their development process. They’ve reported finding more than 200 use cases for LLMs within the Department of Defense.
The United Arab Emirates plans to launch a state-backed AI company by the end of the year.
See also: CAIS website, CAIS twitter, A technical safety research newsletter, An Overview of Catastrophic AI Risks, and our feedback form