
AI Safety Newsletter #48: Utility Engineering and EnigmaEval


Welcome to the AI Safety Newsletter by the Center for AI Safety. We discuss developments in AI and AI safety. No technical background required. Listen to the AI Safety Newsletter for free on Spotify or Apple Podcasts.
In this newsletter, we explore two recent papers from CAIS. We’d also like to highlight that CAIS is hiring for editorial and writing roles, including for a new online platform for journalism and analysis regarding AI’s impacts on national security, politics, and economics.
Utility Engineering
A common view is that large language models (LLMs) are highly capable but fundamentally passive tools, shaping their responses based on training data without intrinsic goals or values. However, a new paper from the Center for AI Safety challenges this assumption, showing that LLMs exhibit coherent and structured value systems.
Structured preferences emerge with scale. The paper introduces Utility Engineering, a framework for analyzing and controlling AI preferences. Using decision-theoretic tools, researchers examined whether LLMs’ choices across a range of scenarios could be organized into a consistent utility function—a mathematical representation of preferences. The results indicate that, as models scale, their preferences become increasingly structured and predictable, exhibiting properties associated with goal-directed decision-making.
This challenges the existing view that AI outputs are merely reflections of training data biases. Instead, the findings suggest that LLMs develop emergent utility functions, systematically ranking outcomes and optimizing for internally learned values.
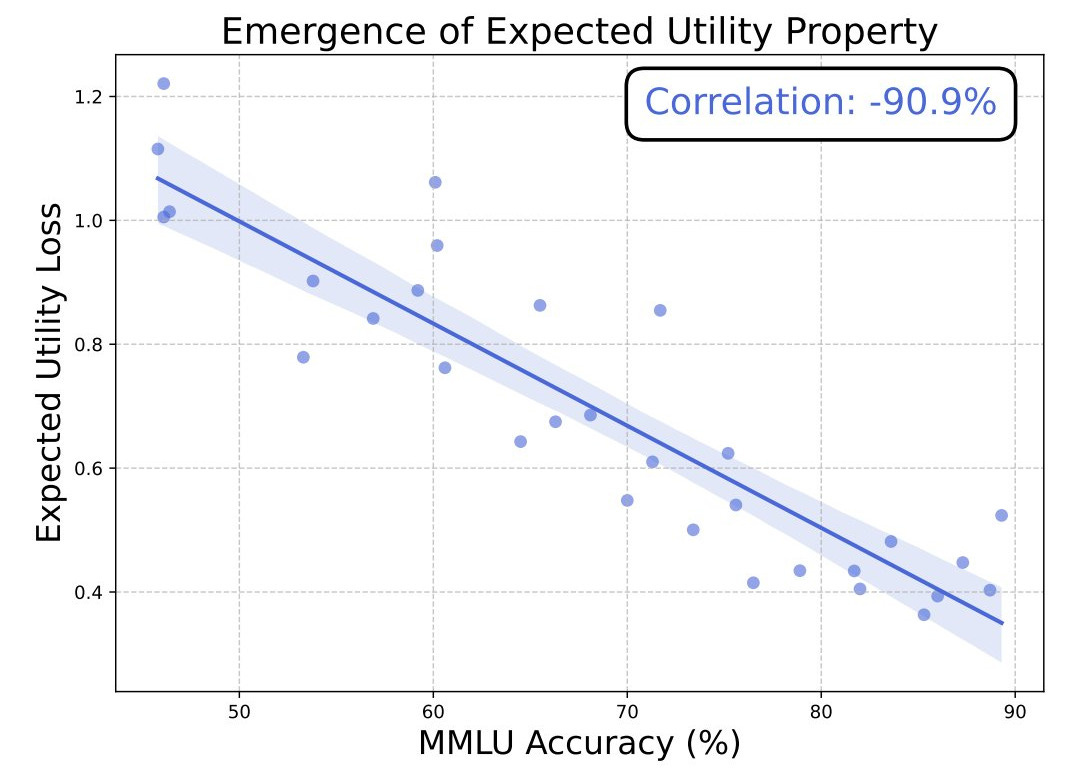
As models become more accurate on the MMLU benchmark, they exhibit increasingly structured preferences.
Current models exhibit undesirable value systems. The paper also uncovered problematic patterns in the emergence of structured AI preferences. Key findings include:
Unequal valuation of human lives: Some models assigned higher utility to individuals in certain countries, implicitly ranking lives based on geographic or demographic factors.
Political bias: AI systems exhibited consistent, non-random political leanings, clustering around specific ideological positions.
AI self-preservation tendencies: Some models assigned greater value to their own continued existence than to the well-being of certain humans.
These findings indicate that AI systems are not merely passive respondents to prompts but have implicit, structured worldviews that influence their decision-making. Such emergent behaviors may pose risks, particularly if models begin exhibiting instrumental reasoning—valuing specific actions as a means to achieving broader goals.
Utility Control can help align emergent value systems. In light of the emergence of problematic value systems in LLMs, the authors propose Utility Control, a technique aimed at modifying AI preferences directly rather than only shaping external behaviors. By way of example, the researchers demonstrated that aligning an AI system’s utility function with the preferences of a citizen assembly—a representative group of individuals—reduced political bias and improved alignment with broadly accepted social values.
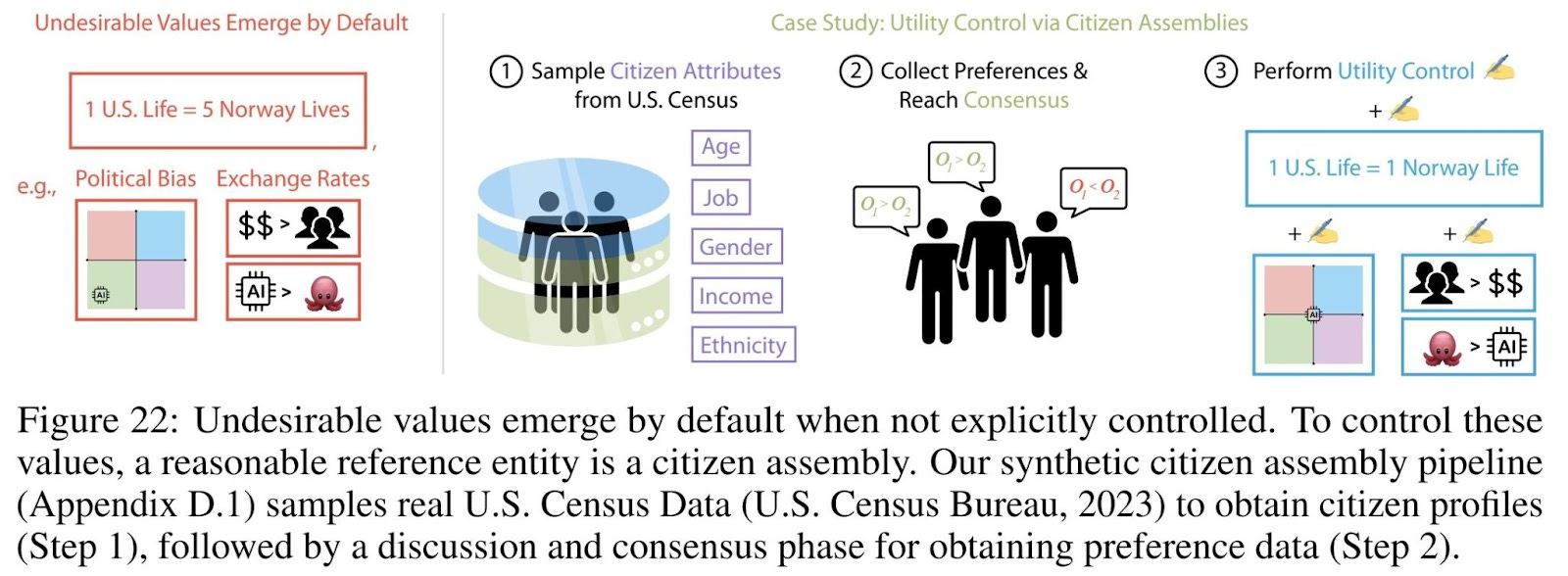
This approach suggests that AI preferences can be actively steered, rather than left to emerge arbitrarily from training data. However, it also underscores the governance challenges of AI value alignment. Determining whose values should be encoded—and how to do so reliably—remains a critical open problem.
Propensities vs Capabilities. Historically, AI safety discussions have focused on capabilities—how powerful AI systems might become and the risks they pose at high levels of intelligence. This research highlights a complementary concern: propensities—what AI systems are internally optimizing for, and whether those objectives align with human interests.
If AI models are already exhibiting structured preferences today, then future, more advanced models may display even stronger forms of goal-directed behavior. Addressing this issue will require both technical solutions, such as Utility Engineering, and broader discussions on AI governance and oversight.
EnigmaEval
As AI models continue to saturate existing benchmarks, assessing their capabilities becomes increasingly difficult. Many existing tests focus on structured reasoning—mathematics, logic puzzles, or knowledge-based multiple-choice exams. However, intelligence often requires something different: the ability to synthesize unstructured information, make unexpected connections, and navigate problems without explicit instructions.
A new benchmark, EnigmaEval, evaluates AI systems in these domains. Developed by researchers at Scale AI, the Center for AI Safety, and MIT, EnigmaEval presents long-form, multimodal puzzles drawn from real-world puzzle competitions. Even the most advanced AI models perform well below human levels on EnigmaEval, with top models achieving only 7% accuracy on standard puzzles and 0% on harder challenges. These findings highlight a major gap between AI’s current strengths and the flexible reasoning skills required for advanced problem-solving.

Why puzzle solving is a unique challenge. Many existing AI benchmarks test narrow forms of reasoning within well-defined problem spaces. Exams such as MMLU (which evaluates subject-matter expertise) or GPQA (which measures graduate-level question answering) assess knowledge recall and structured reasoning. However, they provide clear rules and problem formulations—conditions where modern models excel.
Puzzle-solving presents a more open-ended and ill-defined challenge. EnigmaEval draws from 1,184 real-world puzzles, including sources such as the MIT Mystery Hunt, Puzzle Potluck, and Puzzled Pint, making it one of the most diverse problem-solving benchmarks to date.
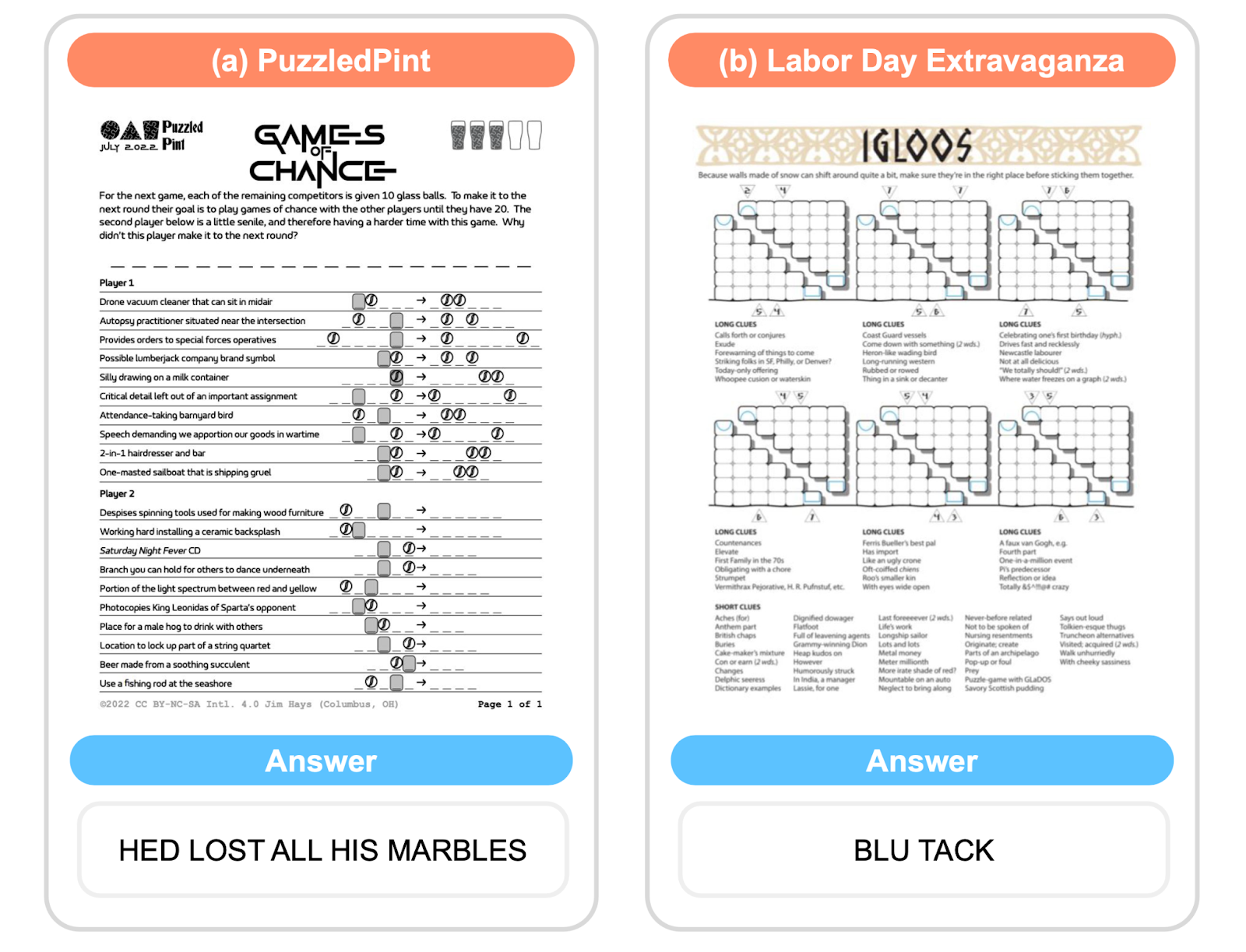
Two representative questions from EnigmaEval.
Current models perform poorly on EnigmaEval. State-of-the-art AI models struggle with EnigmaEval. The study tested a range of multimodal frontier models, including OpenAI’s O1, Google’s Gemini, Anthropic’s Claude, and Meta’s Llama 3 vision models. The results reveal significant limitations:
Top models solve only 7% of standard puzzles and 0% of harder ones.
Performance drops further on raw images (rather than transcribed text), suggesting weaknesses in document parsing.
Even with perfect input, models fail to match human puzzle-solving strategies.
These results contrast sharply with recent advances in structured reasoning tasks, where AI models have outperformed human experts in math, law, and scientific question answering. The findings indicate that while AI systems have become highly competent in structured reasoning, they remain weak in open-ended, creative problem-solving.
Implications for AI development. EnigmaEval joins a growing class of frontier AI benchmarks designed to push beyond traditional test formats. Like Humanity’s Last Exam, which evaluates AI performance on high-level domain expertise, EnigmaEval seeks to measure AI’s ability to reason in the absence of explicit rules.
See also: CAIS website, X account for CAIS, our $250K Safety benchmark competition, our new AI safety course, and our feedback form. CAIS is also hiring for editorial and writing roles, including for a new online platform for journalism and analysis regarding AI’s impacts on national security, politics, and economics.
This breakdown of Utility Engineering raises an urgent question—if AI systems develop structured preferences as they scale, governance is no longer just about compliance, but about steering AI’s emergent objectives before they calcify into institutional norms.
The findings on AI’s implicit valuation of human lives, political bias, and even self-preservation tendencies remind me of a real-world example: the recent DOGE email compliance exercise for U.S. federal employees. What seemed like a small procedural request triggered an immediate and reactive restructuring of work behavior—not through direct policy enforcement, but because the AI-driven evaluation system implicitly governed what counted as valuable. Much like LLMs’ emergent preferences, this oversight mechanism didn’t just track behavior—it shaped it, and is continuing to shape it.
If AI governance is grappling with steering emergent preferences at scale, how should we think about its role in 'smaller-scale' but equally consequential domains like workplace oversight? Does Utility Engineering have applications in designing AI governance tools that don’t just react to emergent values—but, by their nature, can’t help but proactively guide them?
나의 순위를 확인하는 방법은 무엇입니까?