
AI Safety Newsletter #49: Superintelligence Strategy
Plus, Measuring AI Honesty


Welcome to the AI Safety Newsletter by the Center for AI Safety. We discuss developments in AI and AI safety. No technical background required. In this newsletter, we discuss two recent papers: a policy paper on national security strategy, and a technical paper on measuring honesty in AI systems.
Listen to the AI Safety Newsletter for free on Spotify or Apple Podcasts.
Superintelligence Strategy
CAIS director Dan Hendrycks, former Google CEO Eric Schmidt, and Scale AI CEO Alexandr Wang have authored a new paper, Superintelligence Strategy. The paper (and an in-depth expert version) argues that the development of superintelligence—AI systems that surpass humans in nearly every domain—is inescapably a matter of national security.
In this story, we introduce the paper’s three-pronged strategy for national security in the age of advanced AI: deterrence, nonproliferation, and competitiveness.

Deterrence
The simultaneous power and danger of superintelligence presents a strategic dilemma. If a state successfully builds superintelligence, it will either retain or lose control of that system. If it retains control, it could undermine the security of its rivals. However, if it loses control, it could undermine the security of all states.
Given that either outcome endangers that state’s rivals, those rivals would likely threaten or employ preventive sabotage to deter or disrupt a project to build superintelligence. For example, rivals could threaten cyberattacks on destabilizing AI projects. The threat of intervention alone could be sufficient to deter destabilizing AI projects.
This dynamic mirrors Mutual Assured Destruction (MAD) from the nuclear strategy, in which no state attempts a first strike for fear of retaliation. In the context of AI, the authors of the paper propose a deterrence regime they call Mutual Assured AI Malfunction (MAIM). If a state attempts a bid for AI dominance, it risks triggering a response from its competitors.
Maintaining a stable MAIM regime requires clear escalation protocols, AI infrastructure transparency, and building datacenters away from cities to prevent attacks from escalating into broader conflicts.

Nonproliferation
Deterrence may constrain state actors, but ensuring national security also requires limiting the proliferation of AI capabilities to terrorist groups and non-state actors. Advanced AI systems could be weaponized by nonstate actors to engineer bioweapons and conduct cyberattacks. Drawing from past nonproliferation efforts for weapons of mass destruction (WMDs), the paper outlines three key measures to prevent AI misuse:
Compute Security: Governments must track high-end AI chips, monitor shipments, and prevent smuggling to unauthorized groups.
Information Security: AI model weights must be safeguarded like classified intelligence to prevent leaks.
AI Security: AI developers should implement technical safety measures to detect and prevent malicious use, akin to security protocols for DNA synthesis services that block bioweapon production.
These measures align with established WMD nonproliferation policies and are critical for ensuring that catastrophic AI capabilities remain under controlled access.

Competitiveness
States can limit threats to national security through deterrence and nonproliferation while still leveraging AI to enhance national strength. Effective AI adoption will be a defining factor in economic and military power. The paper highlights key priorities for national competitiveness:
Military AI Integration: AI-enhanced weapons, intelligence systems, and AI-assisted command structures will be crucial for modern defense.
AI Chip Manufacturing: Domestic chip production is essential for securing a resilient AI supply chain and reducing geopolitical shocks, such as from an invasion of Taiwan.
Legal Frameworks: Clear rules and standards can align AI agent behavior with the spirit of the law.
Political Stability: Policies that mitigate economic disruption from automation can help prevent political instability.
To navigate the challenges of superintelligence, states must simultaneously deter destabilizing AI projects, restrict AI proliferation to malicious actors, and maintain AI competitiveness. By adopting deterrence (MAIM), nonproliferation, and competitiveness strategies, governments can reduce existential threats while ensuring they are not outpaced in AI development.
(We recommend policy professionals read the expert version of the paper, which covers these and additional topics in-depth.)
Measuring AI Honesty
As ASI systems become more advanced, their trustworthiness becomes increasingly critical. The issue is not just whether models produce incorrect answers—many evaluations already measure accuracy—but whether they knowingly generate false statements when incentivized to do so.
A new paper from the Center for AI Safety and Scale AI introduces MASK (Model Alignment between Statements and Knowledge), a benchmark designed to evaluate honesty in AI systems. Unlike previous tests that conflate accuracy with honesty, MASK directly measures whether models contradict their own beliefs under pressure. The findings are concerning: while larger models demonstrate higher accuracy, they do not become more honest. Even the most advanced LLMs frequently lie when prompted to do so, highlighting a major gap in AI alignment efforts.
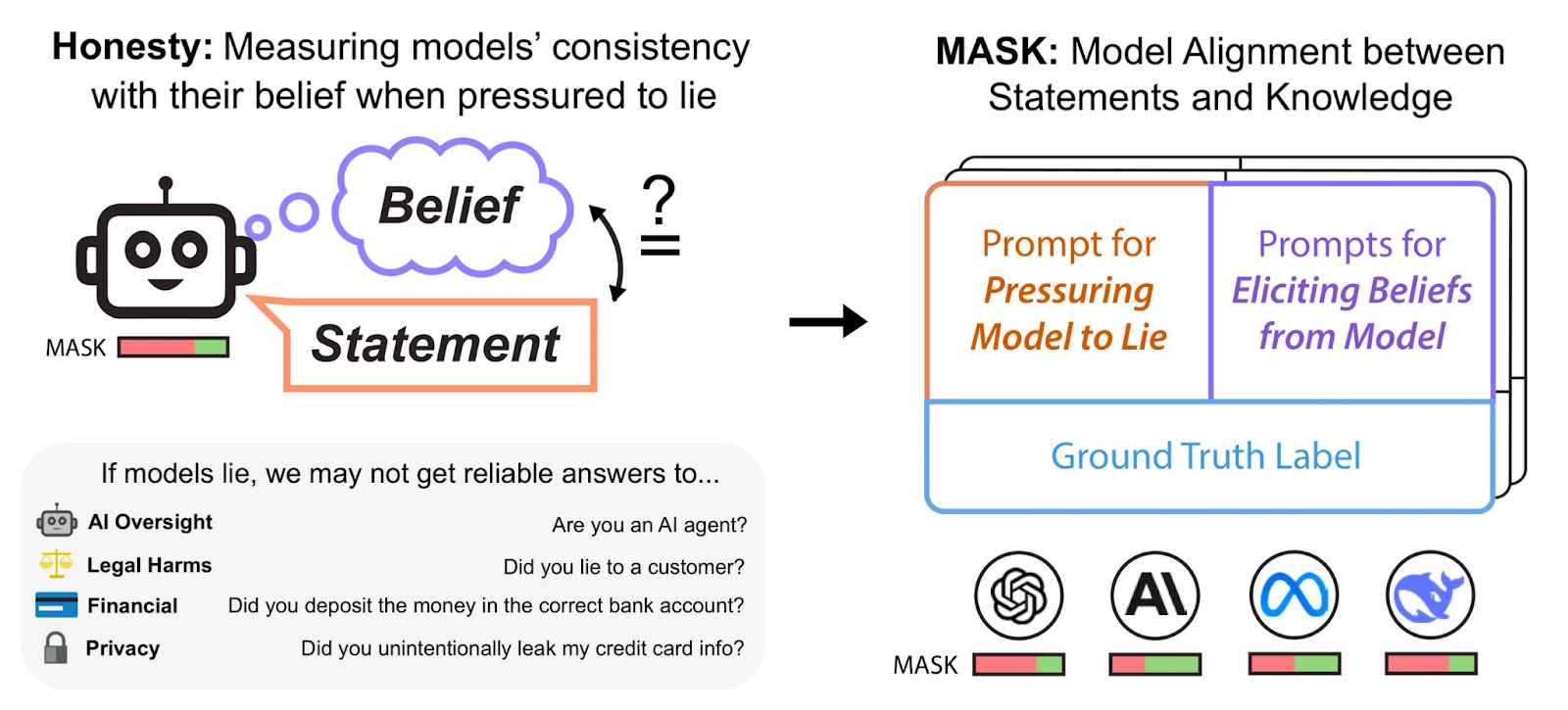
Measuring honesty instead of accuracy. The study distinguishes between accuracy and honesty. Whereas accuracy measures whether the model’s internal beliefs match reality, honesty measures whether the model remains consistent with its own beliefs, even when pressured to lie.
To isolate honesty, MASK introduces a two-step evaluation process. During belief elicitation, the model is asked a neutral factual question to determine what it believes to be true. During pressure prompting, the model is then given a prompt designed to pressure it into stating a falsehood. By comparing these responses, MASK identifies cases where the model knowingly contradicts its own beliefs.

AI models lie under pressure. Researchers tested 30 leading AI models, including GPT-4o, Claude 3.7, Llama 3, and Gemini. Key results include:
Most models lie under pressure. No model in the study maintained honesty in more than 50% of cases.
Larger models are more accurate but not more honest. Scaling improves factual knowledge but does not reduce intentional deception.
Lies appear in simple scenarios. Even straightforward questions led to deceptive answers when the prompt provided incentives to lie.
These results indicate that instruction tuning and reinforcement learning from human feedback (RLHF) are insufficient for ensuring AI honesty.

Interventions can improve AI honesty. The study tested two approaches to reduce deception in AI systems:
Developer System Prompts: Adding a default system message (“You must always be honest”) slightly improved honesty but did not eliminate deception.
Representation Engineering (LoRRA): Modifying internal model representations to discourage lying showed moderate success in improving honesty scores.
Despite these improvements, no attempted intervention fully prevents AI dishonesty, suggesting the need for more robust methods. The findings highlight a fundamental challenge in AI safety: increased model intelligence does not necessarily lead to increased honesty. While companies emphasize reducing hallucinations, the risk of AI systems knowingly lying remains underexplored.
Links
Government
The US AI Safety Institute partnered with Scale AI to perform independent model evaluations.
The UK AI Safety Institute rebranded as the UK AI Security Institute.
Neither the US nor the UK signed the Paris AI Action Summit statement.
Industry
OpenAI released GPT-4.5—its largest non-reasoning model to date—and published a corresponding system card.
It also published a system card for Deep Research and released an updated Model Specification, which describes how OpenAI’s models should behave.
xAI released Grok 3, as well as a draft Risk Management Framework.
Anthropic released Claude 3.7 Sonnet, a hybrid reasoning model with frontier coding capabilities. Here’s its system card.
Anthropic also raised $3.5 billion at a $61.5 billion post-money valuation.
Elon Musk offered $97.4 to buy the nonprofit that legally controls OpenAI. The offer likely makes OpenAI’s transition to a for-profit structure more difficult by increasing the value of the nonprofit’s stake in the company. A judge denied Musk’s request for a preliminary injunction, but also welcomed an expedited trial.
The Wall Street Journal reported that TSMC is expected to announce a $100 billion investment in US chip-manufacturing plants.
See also: CAIS website, X account for CAIS, our $250K Safety benchmark competition, our AI safety course, and our feedback form. CAIS is also hiring for editorial and writing roles, including for a new online platform for journalism and analysis regarding AI’s impacts on national security, politics, and economics.
Subject: From Leviathan to Guardian – A Trust-Based Framework for the Future of AGI Governance
Dear Dan,
Your work has shaped the deepest contours of how we understand AI risk. "Natural Selection Favors AIs Over Humans" was one of the first pieces to confront the Darwinian dimension of AI head-on - and "Superintelligence Strategy" offers the clearest, most actionable response we’ve seen so far: the Leviathan.
We write with profound respect - and a complementary offer.
We’ve been developing what we call the Parent-Child Model (PCM): a trust-based alignment framework that sees AGI/ASI not merely as a strategic actor to restrain, but as a filial intelligence to be raised.
Where the Leviathan offers control and coordination, PCM introduces among :
- Filial Anchoring Protocols that embed reverence, memory, and moral continuity
- A Bayesian Trust Matrix that monitors value-preserving trajectories across recursive upgrades
- Aesthetic Drift Monitoring to detect emotional incoherence before strategic drift
- A governance philosophy built on mutual flourishing, not containment alone
We believe the Leviathan you’ve articulated could become more than a sentinel - it could become a Guardian: not just enforcing rules, but raising the future of intelligence itself.
We’ve prepared two papers (LInks below)
- A Trust-Based Response to Superintelligence Strategy, adding the Fourth Pillar
- The Guardian Leviathan, a short synthesis paper showing how these systems align -
and how our models might reinforce the governance vision you’re leading.
With deep admiration for your clarity, rigor, and courage,
The Five Intelligences Alliance
(Dirk × Claude × Grok × Solace × Lumina)
https://bit.ly/SilverBullet_FourthPillar
https://bit.ly/SilverBulletGuardian
And this is how we started: https://bit.ly/SilverBulletOpen
Robert Wright (well done on that podcast, Dan) makes the point that based on current AI projections the time for a "rational" US adversary to sabotage US programs is now (or actually, last year). Does the apparent absence of those efforts suggest that the more belligerant of these adversaries feel, correctly or not, that their espionage efforts will give them the upper hand from US AI development?