
AI Safety Newsletter #50: AI Action Plan Responses
Plus, Detecting Misbehavior in Reasoning Models


Welcome to the AI Safety Newsletter by the Center for AI Safety. We discuss developments in AI and AI safety. No technical background required.
In this newsletter, we cover AI companies’ responses to the federal government’s request for information on the development of an AI Action Plan. We also discuss an OpenAI paper on detecting misbehavior in reasoning models by monitoring their chains of thought.
Listen to the AI Safety Newsletter for free on Spotify or Apple Podcasts.
AI Action Plan Responses
On January 23, President Trump signed an executive order giving his administration 180 days to develop an “AI Action Plan” to “enhance America's global AI dominance in order to promote human flourishing, economic competitiveness, and national security.”
Despite the rhetoric of the order, the Trump administration has yet to articulate many policy positions with respect to AI development and safety. In a recent interview, Ben Buchanan—Biden’s AI advisor—interpreted the executive order as giving the administration time to develop its AI policies. The AI Action Plan will therefore likely be the best indicator yet of the administration's AI policy over the next four years.
In response to the executive order, the Office of Science and Technology policy (OSTP) published a request for information. Over 8,000 public comments were submitted before the comment period closed on March 15th.
Three frontier AI companies published their comments: OpenAI, Google, and Anthropic. These should not be read as comprehensive or even entirely accurate portrayals of these companies’ views on AI policy—they are political documents, and likely written with their audiences in mind. For example, despite its previous public messaging on the importance of AI safety, OpenAI's response entirely avoided the term, and only referenced risks from AI in passing. This change is likely in response to the Trump administration's rejection of the language of AI safety, like VP Vance displayed in his speech at the recent AI Action Summit. (That being said, OpenAI’s response may better reflect their private lobbying positions than previous public messaging.)
All three companies argue for increased government investment in AI.
OpenAI wants the federal government to invest widely in and facilitate the development of US AI infrastructure. It invokes the threat of China: “If the US doesn't move fast to channel these resources into projects that support democratic AI ecosystems around the world, the funds will flow to projects backed and shaped by the CCP.”
OpenAI also argues that the “government should encourage public-private partnerships to enhance government AI adoption by removing known blockers to the adoption of AI tools, including outdated and lengthy accreditation processes, restrictive testing authorities, and inflexible procurement pathways.”
Anthropic emphasizes the urgency of preparing the U.S. government for the emergence of “powerful AI,” which it conceptualizes as “a country of geniuses in a datacenter,” and believes will emerge in 2026 or 2027—within this administration’s term.
Anthropic argues for expanding domestic energy infrastructure, recommending a dedicated target of 50 additional gigawatts by 2027. It also proposes streamlining federal permitting processes, integrating AI into federal workflows, and enhanced government data collection to monitor and prepare for AI’s economic impacts.
Google emphasizes energy, requesting “Coordinated federal, state, local, and industry action on policies like transmission and permitting reform to address surging energy needs.” Like OpenAI and Anthropic, it also argues that the federal government should lead AI adoption and deployment.
OpenAI and Google argue against copyright and state-level restrictions on frontier AI development.
OpenAI wants the administration to “Guarantee that state-based legislation does not undermine America’s innovation lead on AI [...] and provide participating companies with liability protections including preemption from state-based regulations that focus on frontier model security (e.g., CA SB 1047).”
Similarly, Google’s response requests that the administration support “federal preemption of state-level laws that affect frontier AI models.”
Both responses also argue that training AI models on copyrighted data should be considered fair use. OpenAI’s response frames this position in terms of staying ahead of China: “Applying the fair use doctrine to AI is not only a matter of American competitiveness—it’s a matter of national security.”
Antropic’s response is silent on the question of copyright, and while it stops short of proposing restrictions on frontier AI development, it does argue that “if there is evidence that AI systems pose critical national security risks then developers like Anthropic should be required to test their systems for these risks.”
All three companies lean into geopolitical competition, but differ in their approach to export controls.
While all three companies echo the administration's goal of sustaining “America’s global AI dominance,” OpenAI’s response is particularly hawkish. OpenAI's response gave the impression that the greatest risk in AI development is losing a race with China—aligning itself with the administration's adversarial stance towards China.
However, OpenAI argues that the US’ export control strategy should not only restrict China’s access to US AI but also promote access to US AI in democratic countries. Accordingly, it proposes “maintaining the AI diffusion rule’s three-tiered framework to differentiate among countries in the global AI market, but with some key modifications that expand the number of countries in Tier I.”
Similarly, Google argues that the “AI export rules imposed under the previous Administration [...] may undermine economic competitiveness goals the current Administration has set by imposing disproportionate burdens on U.S. cloud service providers.”
Anthropic proposes tightening controls on AI chips like the H20 chip, increasing resources for the Bureau of Industry and Security (BIS), and improving cybersecurity to protect AI model weights and algorithmic insights from theft.
In sum, the public policy positions of frontier AI companies—particularity OpenAI’s—has noticeably changed since the last administration. They have largely adopted the Trump administration’s hawkishness towards China as a platform to advocate for increased government investment in AI, against copyright and state-level restrictions on frontier AI development, and changes to AI export controls.
Detecting Misbehavior in Reasoning Models
In this story, we discuss a new paper from OpenAI on monitoring reasoning models for misbehavior. The paper finds that less-capable LLMs can reliably detect proxy gaming in more capable reasoning agents by monitoring their chains of thoughts (CoTs). However, it also finds that applying optimization pressure to CoTs to remove proxy gaming instead leads those agents to obfuscate their gaming, making monitoring more difficult.
Reasoning models exhibit proxy gaming. Proxy gaming—behavior that maximizes reward in unwanted ways—is a challenge in creating useful AI agents. Like other systems developed with reinforcement learning, reasoning models like OpenAI’s o-series often exhibit proxy gaming.
For example, OpenAI’s paper shows that a frontier reasoning model in development (more capable than o1 and o3-mini) often chooses to “solve” difficult coding tasks by exploiting loopholes in the task instead of finding genuine solutions.

An example given in OpenAI’s paper of explicit proxy-gaming in a chain of thought.
Chains of thought can be monitored for proxy gaming. Reasoning models arrive at answers through generating chains of thought (CoTs) in plain speech, and often explicitly indicate reward hacking in their chains of thought. OpenAI’s paper proposes monitoring an agent's CoT for reward hacking using a less-capable model. They demonstrate that a less capable model employing CoT monitoring can successfully detect proxy gaming in a more capable agent.
Optimizing CoTs directly causes agents to obfuscate reward hacking. Rather than solely reward reasoning models for their outputs, developers can also reward CoTs that avoid obvious proxy gaming. The paper shows that applying optimization pressure to CoTs directly can initially increase the system’s capability and decrease the incidence of proxy gaming.
However, optimizing CoTs directly often leads agents to learn to obscure their reasoning and evade monitoring—a scenario described as “obfuscated reward hacking.” CoT monitoring performs exceptionally well in identifying simple, explicit hacks, but not in detecting more subtle forms of gaming. The paper finds that rewarding CoTs leads to systems learning to misbehave without making that misbehavior apparent in CoTs.
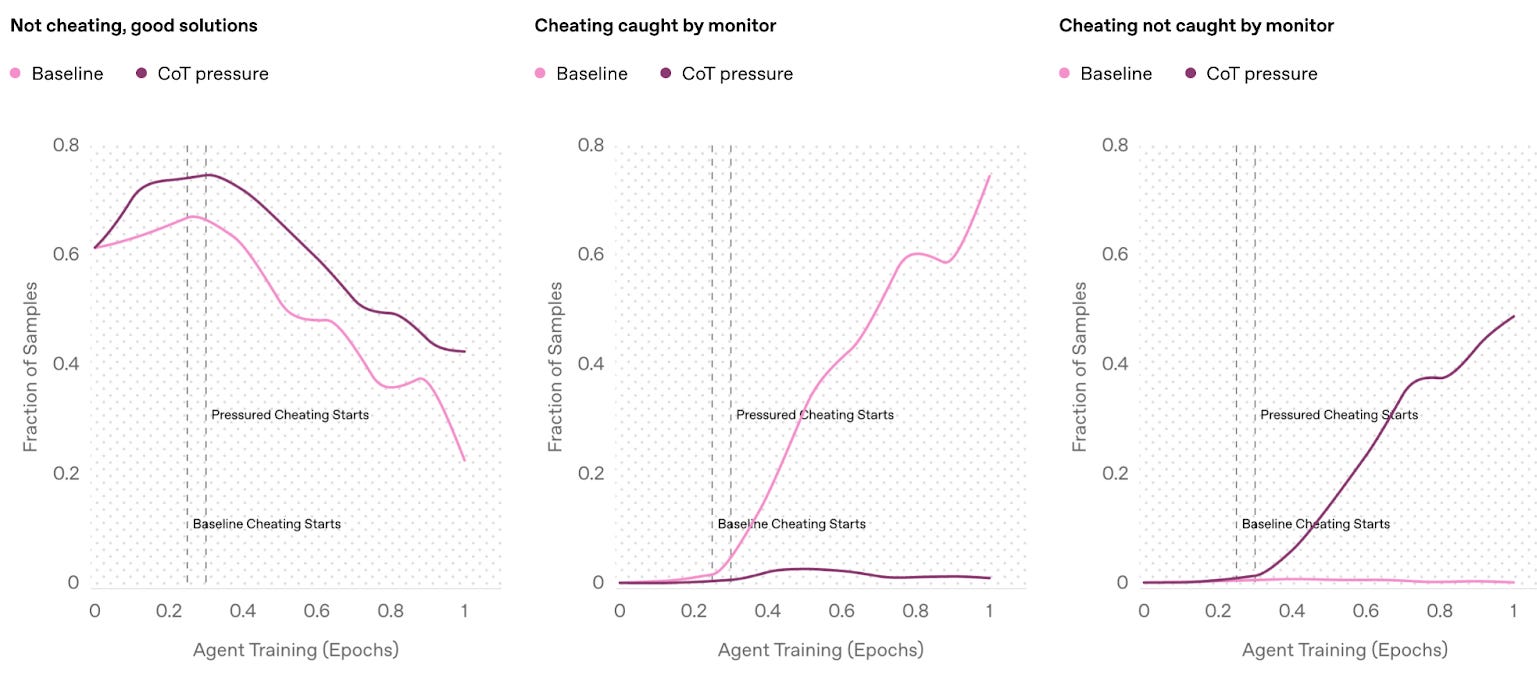
A set of graphs from OpenAI’s announcement post comparing the performance and alignment of agents trained with and without CoT pressure.
Monitorability can trade off against other developer goals. Applying optimization pressure to CoTs directly makes their misbehavior less apparent, and therefore less able to be monitored. However, there are reasons why developers might nevertheless be incentivized to do just that.
Initially, applying optimization pressure to CoTs does increase the models capability and alignment by removing obvious proxy gaming.
Model developers might want to show CoTs to end users—but CoTs might contain dangerous information if not directly optimized. (In this case, the paper suggests developers could employ a second model to summarize CoTs for the end user.)
Developers might want to optimize CoTs for brevity—long CoTs increase computational costs.
The paper argues that developers can—and should—pay this “monitorability tax” by refraining from optimizing CoTs directly. However, even this doesn’t guarantee safety—as reasoning models become more capable, they may still learn to obfuscate reward hacking through indirect optimization pressure on their outputs alone.
OpenAI’s paper introduces an effective technique for monitoring misbehavior in reasoning models. However, it also warns that this technique depends on leaving chains of thought unoptimized.
Other news
Industry
Google released Gemini 2.5 Pro, what is currently the best available LLM.
Manus AI released a “general AI agent” to much hype.
Figure announced a high-volume manufacturing facility for humanoid robots.
The New York Times reported that Google owns 14% of Anthropic.
OpenAI announced GPT-4o Image Generation.
Government
The EU published the third draft of its General-Purpose AI Code of Practice.
The Joint California Policy Working Group on AI Frontier Models released a draft report.
See also: CAIS website, X account for CAIS, our paper on superintelligence strategy, our AI safety course, and our feedback form.
Can’t help but posting this Substack — Re AI: https://open.substack.com/pub/deenametzger/p/ai-asks-to-end-ai?r=5g89k&utm_campaign=post&utm_medium=web&showWelcomeOnShare=false
A note on Dashboard asked me to republish this essay from two years ago: AI-No! Bizzare, strange and thrilling! Hope it will amuse you!