
AI Safety Newsletter #56: Google Releases Veo 3
Plus, Opus 4 Demonstrates the Fragility of Voluntary Governance


Welcome to the AI Safety Newsletter by the Center for AI Safety. We discuss developments in AI and AI safety. No technical background required.
In this edition: Google released a frontier video generation model at its annual developer conference; Anthropic’s Claude Opus 4 demonstrates the danger of relying on voluntary governance.
Listen to the AI Safety Newsletter for free on Spotify or Apple Podcasts.
Google Releases Veo 3
Last week, Google made several AI announcements at I/O 2025, its annual developer conference. An announcement of particular note is Veo 3, Google’s newest video generation model.
Frontier video and audio generation. Veo 3 outperforms other models on human preference benchmarks, and generates both audio and video.

If you just look at benchmarks, Veo 3 is a substantial improvement over other systems. But relative benchmark improvement only tells part of the story—the absolute capabilities of systems ultimately determine their usefulness. Veo 3 looks like a marked qualitative improvement over other models—it generates video and audio with extreme faithfulness, and we recommend you see some examples for yourself. Veo 3 may represent the point video generation crosses the line between being an interesting toy and being genuinely useful.
Other announcements at I/O 2025. Other highlights from the conference include:
Gemini 2.5 Pro now leads LMArena and WebDev Arena. Deep Think mode, a reasoning feature that scored 49.4% on the USA Mathematical Olympiad 2025 (more than twice OpenAI’s o3, which scored 21.7%). Gemini 2.5 Flash now performs better across reasoning, multimodality, code, and long context while becoming 20-30% more efficient in token usage.
Gemini Diffusion, an experimental (non-frontier) text diffusion model, delivers output 4-5 times faster than comparable models while rivaling the performance of models twice its size. Most LLMs are autoregressive models, which generate one token at a time—in contrast, diffusion models generate an entire response at once.
Google also announced Gemma 3n, an open model small enough to run on mobile devices, a public beta for Google’s autonomous coding agent Jules, a new AI search feature, an AI watermarker that identifies content generated by Google’s systems, and more.
AI is here to stay. AI use is sometimes driven by trends—for example, ChatGPT added a million users in an hour during the ‘Ghiblification’ craze. However, as AI systems become genuinely useful across more tasks, they will become ubiquitous and enduring. Google’s Gemini app now has 400M monthly active users, and its AI products now process over 480 trillion tokens a month—up from 9.7 trillion last year.
Opus 4 Demonstrates the Fragility of Voluntary Governance
Last week, Anthropic released Claude Opus 4 and Claude Sonnet 4. Both exhibit broadly frontier performance, and lead the field on coding benchmarks. Claude Opus 4 is also Anthropic’s first model to meet its ASL-3 safety measure, which designates models that pose substantial risk. However, Anthropic rolled back several safety and security commitments prior to releasing Opus 4, demonstrating that voluntary governance is not to be relied on.
Opus 4 exhibits hazardous dual-use capabilities. In one result from its system card, Opus 4 provides a clear uplift in trials measuring its ability to help malicious actors acquire biological weapons.
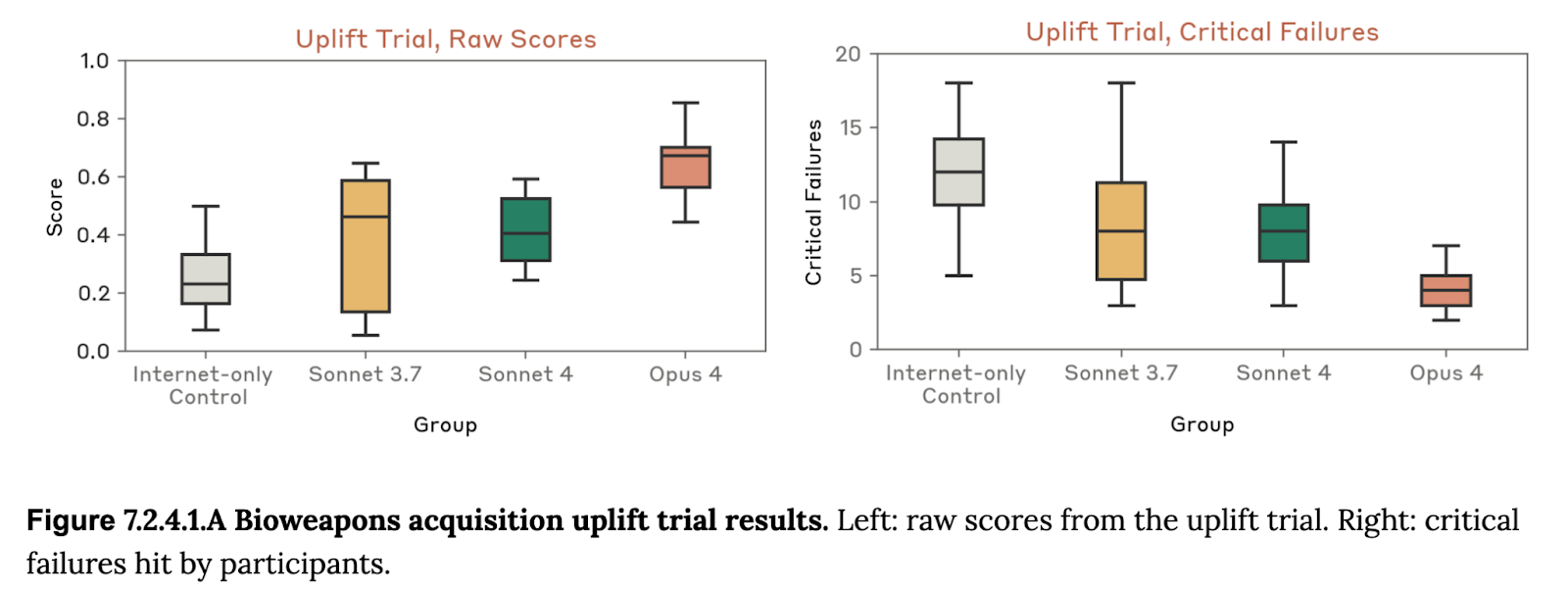
Anthropic’s Chief Scientist Jarad Kaplan told TIME that malicious actors could use Opus 4 to “try to synthesize something like COVID or a more dangerous version of the flu—and basically, our modeling suggests that this might be possible.” It’s not just Opus 4: several frontier models outperform human experts in dual-use virology tests.
The system card also reports that Apollo Research found an early Claude Opus 4 version exhibited "scheming and deception," advising against its release. Anthropic says it implemented internal fixes; however, it doesn’t appear that Anthropic had Apollo Research re-evaluate the final, released version.
Anthropic’s safety protections may be insufficient. In light of Opus 4’s dangerous capabilities, Anthropic rolled out ASL-3 safety protections. However, early public response to Opus 4 indicates that those protections might be insufficient. For example, one researcher showed that Claude Opus 4's WMD safeguards can be bypassed to generate over 15 pages of detailed instructions for producing sarin gas.
Anthropic walked back safety and security commitments prior to Opus 4’s release. Anthropic has also faced criticism for walking back safety commitments prior to Opus 4’s release. For example, Anthropic’s September 2023 Responsible Scaling Policy (RSP) committed to define detailed ASL-4 "warning sign evaluations" before their systems reached ASL-3 capabilities; however, it hadn’t done so at the time of Opus 4’s release. This is because Anthropic redlined that requirement in an October 2024 revision to its RSP.
Anthropic also weakened its ASL-3 security requirements shortly before Opus 4's ASL-3 announcement, specifically no longer requiring robustness against employees stealing model weights if they already had access to "systems that process model weights."
Voluntary governance is fragile. Whether or not Anthropic’s changes to its safety and security policies are justified, voluntary commitments are not sufficient to ensure model releases are safe. There’s nothing stopping Anthropic or other AI companies from walking back critical commitments in the face of competitive pressure to rush releases.
Government
JD Vance discussed why he’s worried about AI in a recent interview.
A judge ruled that Character.AI is a product for the purposes of product liability in a lawsuit over a boy’s suicide after interacting with a Character.AI chatbot.
Industry
OpenAI bought iPhone designer Jony Ive’s startup, io, for $6.5 billion.
Civil Society
Peter N. Salib and Simon Goldstein argue that today’s AI systems aren’t paperclip maximizers.
Devid Kirichenko writes about how drones are eroding the norms of war.
ARC Prize released a new reasoning benchmark, ARC-AGI-2, on which frontier reasoning models score in low single-digits.
CSET is funding research on risks from internal deployment of frontier AI models.
A new paper found that Claude Sonnet 3.5 is significantly more persuasive than humans.
An Axios poll found that 77% of Americans want AI companies to slow down.
See also: CAIS’ X account, our paper on superintelligence strategy, our AI safety course, and AI Frontiers, a new platform for expert commentary and analysis.
In a time where AI is advancing at unprecedented speed, a few voices are quietly choosing a harder path:
One that puts safety before scale. Wisdom before hype. Humanity before power.
There’s a new initiative called Safe Superintelligence Inc. — a lab built around one single goal:
To develop AGI that is safe by design, not just by hope or regulation.
Created by Ilya Sutskever
If you're someone with world-class technical skills and the ethical depth to match —
this is your call to action.
We don’t need more AI.
We need better, safer, more compassionate AI.
Spread the word. Support the mission