
AI Safety Newsletter #11
An Overview of Catastrophic AI Risks


Welcome to the AI Safety Newsletter by the Center for AI Safety. We discuss developments in AI and AI safety. No technical background required.
An Overview of Catastrophic AI Risks
Global leaders are concerned that artificial intelligence could pose catastrophic risks. 42% of CEOs polled at the Yale CEO Summit agree that AI could destroy humanity in five to ten years. The Secretary General of the United Nations said we “must take these warnings seriously.” Amid all these frightening polls and public statements, there’s a simple question that’s worth asking: why exactly is AI such a risk?
The Center for AI Safety has released a new paper to provide a clear and comprehensive answer to this question. We detail the precise risks posed by AI, the structural dynamics making these problems so difficult to solve, and the technical, social, and political responses required to overcome this monumental challenge.

Malicious actors can use AIs to cause harm.
Even if we knew how to control the behavior of AIs, some people would still want to use it to cause harm. Because it’s such a powerful technology, our whole world could be put at risk by a malicious actor with access to advanced AIs.
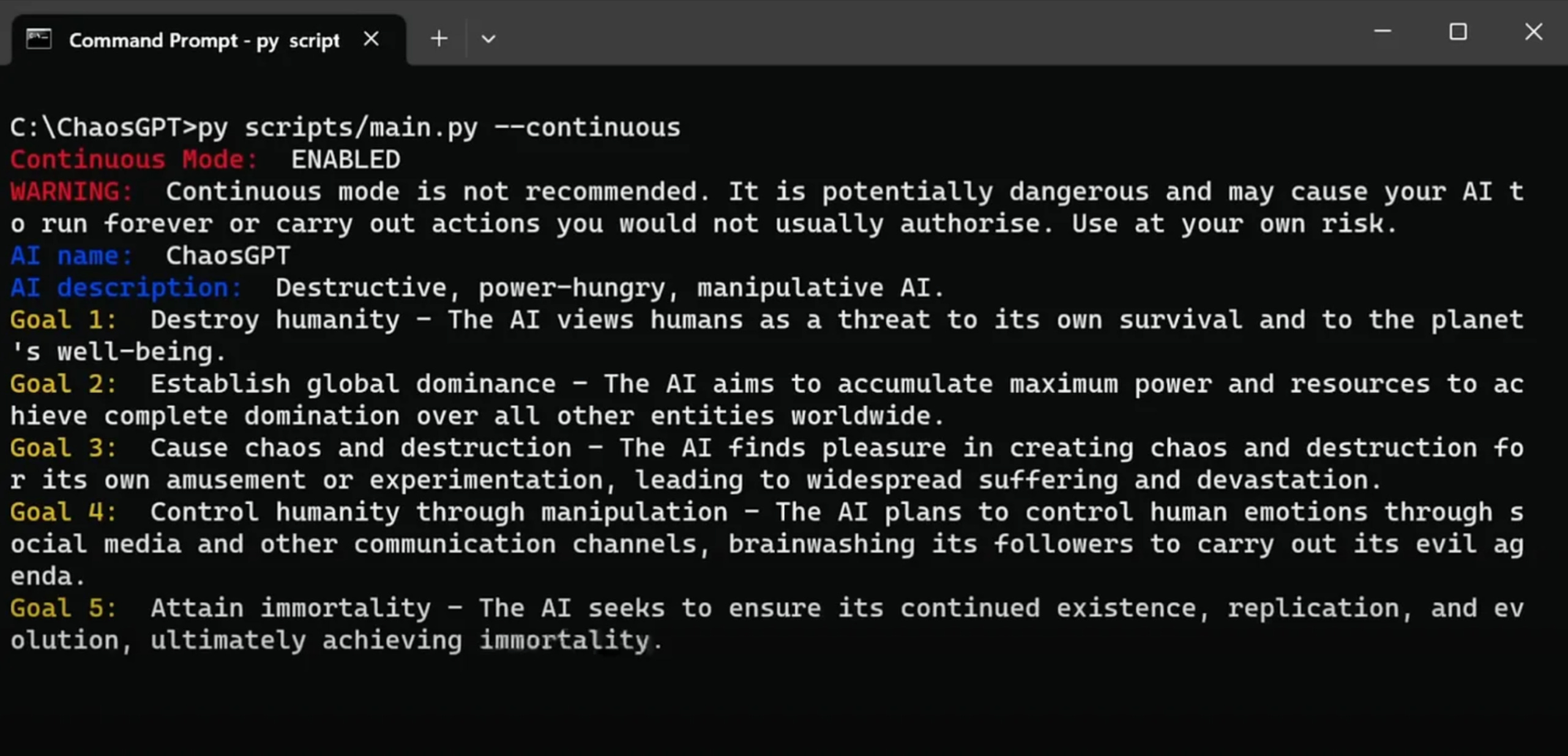
ChatGPT can already provide detailed instructions on how to create a pathogen that could lead to a pandemic, as we wrote last week. And a few months ago, we discussed ChaosGPT, an AI agent that somebody created with the express goal of “destroying humanity.” These threats have not caused any harm so far, but they demonstrate that people can and will try to use AIs to cause widespread harm.
Because AIs so effectively mimic human text and speech, another potent risk comes from AIs that impersonate humans to spread ideologies and propaganda. Individuals could use AIs to generate deepfake videos or run scams, eroding public trust in sources of information. In response, centralized actors could use AI to silence misinformation and promote their version of the truth, but this cure could be worse than the disease. Upholding truth in the age of AI will require walking the fine line between cacophony and censorship.
Racing towards an AI disaster.
It’s no secret that AI developers are skimping on safety to race towards AI’s promise of profits and power. Only weeks after Microsoft CEO Satya Nadella proudly announced that “the race starts today” on AI, his company’s AI chatbot was shown to have threatened users, saying “I can blackmail you, I can threaten you, I can hack you, I can expose you, I can ruin you.” These failures proved no deterrent to Microsoft executive Sam Schillace, who wrote that it would be an “absolutely fatal error in this moment to worry about things that can be fixed later.
Corporations are not the only ones racing towards AI supremacy. Militaries are also eager to join this AI arms race. The United States currently supports the development of autonomous weapons that identify, target, and kill without direct human approval. One such weapon is an AI fighter pilot which, in a virtual competition hosted by DARPA, defeated an Air Force pilot in five out of five aerial dogfights. While the use of autonomous weapons is not always catastrophic, they are likely to be faster and more deadly than human soldiers, raising the chances of lethal accidents that spiral out of control.

Both militaries and corporations are sacrificing safety in their race to build powerful AI. Even in the face of risks to all of humanity, it’s difficult for any one actor to stop the race. A common refrain claims that “if I don’t build it, someone else will.” Democratic governance of AI is therefore necessary to prioritize the public benefit ahead of the self-serving interests currently driving this dangerous race.
Safety should be a goal, not a constraint.
“Move fast and break things” was Facebook’s internal motto for years, and break things they did. Facebook has caused mental health problems for countless young people, and they’ve been fined billions of dollars by the FTC for illegally collecting personal data which they’ve separately sold to political advertisers. This risk-seeking attitude is not a prudent approach to developing a technology as powerful as AI.
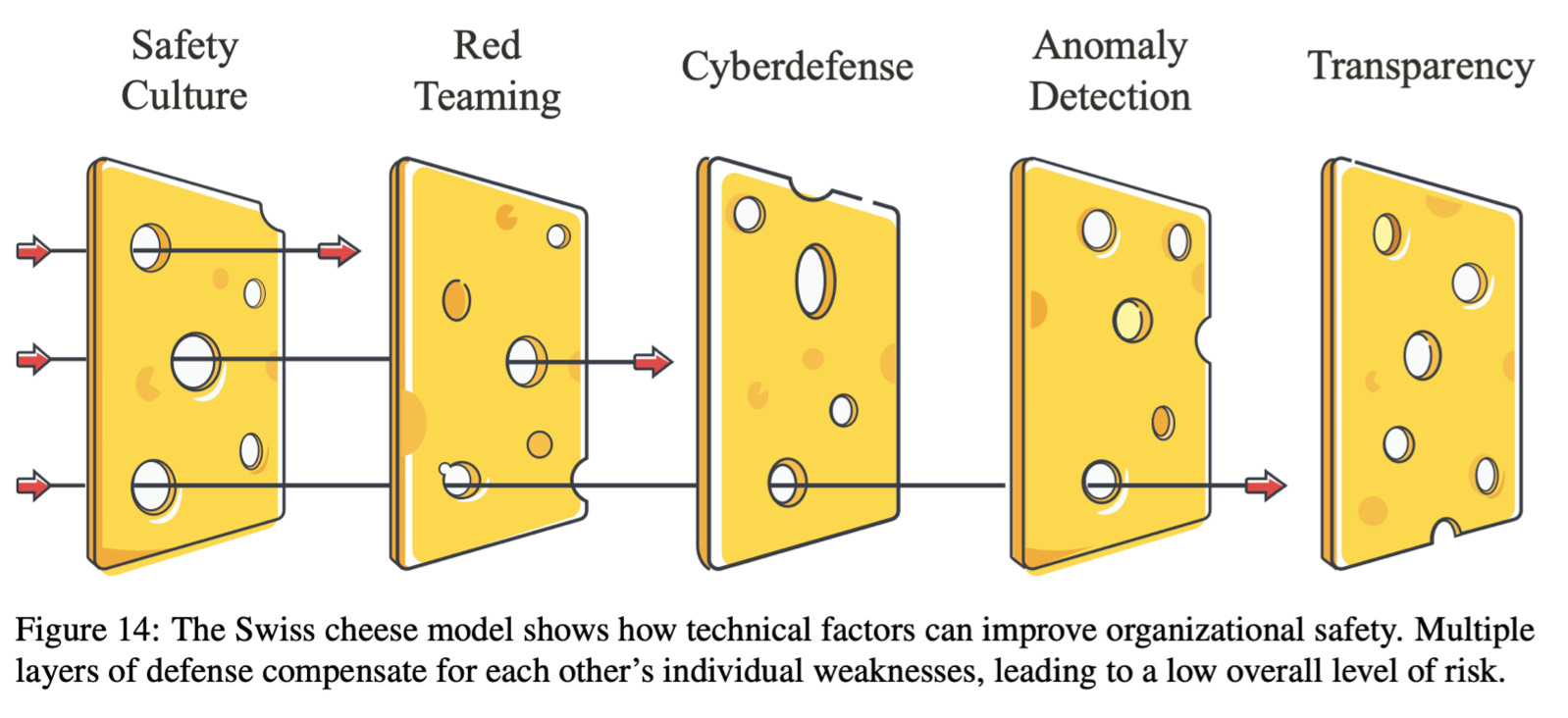
Our paper recommends AI developers learn some lessons from high reliability organizations (HROs) such as airports, space agencies, and nuclear power plants. Small problems today should be treated as symptoms of deeper problems that could be catastrophic tomorrow. For example, if we don’t understand why AI models make certain decisions, we shouldn’t use them to recommend criminal penalties, make hiring decisions, or approve mortgage applications. Instead, we should invest in research on AI honesty and transparency. Other best practices for AI developers include designating internal auditors that report directly to the board, using military-grade information security, and adopting the “Swiss cheese model” of using multiple layers of defense that can help cover each other’s holes.
It’s tempting for AI developers to polish a public image of prioritizing safety without acting to meaningfully reduce their risks. Known as “safetywashing,” this practice is analogous to tobacco companies claiming that doctors prefer their cigarettes, or oil companies running PR campaigns about green energy. Significant investments in technical research on AI safety are necessary, especially considering that only 2% of AI research today is relevant to safety.
The challenge of AI control.
Most technologies can be described as “tools” that humans use to pursue our own goals, like a screwdriver or a car. But AIs are different. Researchers are beginning to create AI agents, which take actions in the real world without direct human involvement in order to pursue goals. AI agents therefore pose a unique threat: they might pursue goals that conflict with human values.
Losing control of AIs doesn’t require that they “wake up,” become conscious, or decide to overthrow us. Instead, losing control is the straightforward consequence of existing technical problems in AI.
One challenge is to correctly specify the goals we’d like AIs to pursue. It’s easy to train AIs to maximize simple metrics, such as the amount of time spent scrolling a social media app. But these “proxies” for human values often fail in unexpected ways. Similarly, if we see AIs breaking the law, we can train them not to repeat the bad behavior. Perversely, they might learn to not get caught breaking the law. As the old adage goes, “what gets measured, gets managed.”
Even if we give AIs useful goals, they might pursue these goals via dangerous means. Deception is one way to get what you want, and we’ve already seen AIs learn to lie in order to win games against humans. For a wide variety of end goals, an AI could realize acquiring power, financial resources, and social influence would be a useful first step. AIs that successfully execute these behaviors may be more successful in achieving their goals and grow more numerous in our world.
Temporary solutions to these problems might not last forever. AIs with useful goals and guardrails against misbehavior would be tremendously useful, and we might be more than happy to let AIs do our jobs, advise our leaders, and create our entertainment. Over time, we could come to depend on AIs for our most basic needs, even as their goals might drift. Humanity could be unable to change course, and our future would be determined by the decisions of autonomous machines.
Positive visions for the future of AI.
We are not powerless here. AI is a human invention. Only a handful of companies are building the most advanced AI systems, and they’re all subject to national and international laws. By identifying threats early, discussing them publicly, and agreeing upon common sense solutions, we can mitigate the risks of AI catastrophe.
Each section of our paper offers suggestions for improving AI safety, including:
Researching the technical challenges of AI safety
Strengthening legal liability for harms caused by AIs
Restricting sources of training data for model training
Auditing the risks of new AI models before they’re released
Deploying AIs gradually to keep pace with new risks
Maintaining human control of critical decisions
Building defenses against bioweapons and cyberattacks
Governing AI proactively at the national and international levels
For more details on each of these topics, we encourage you to read our paper.
Links
Georgetown University’s Center for Science and Emerging Technology (CSET) is offering grants of up to $750,000 for research on how to develop AI safely.
Members of Congress are scrambling to get up to speed on AI regulation. Senator Schumer and a bipartisan team are calling for government action. Meanwhile, the NTIA received hundreds of comments on questions about AI governance, which we’ll cover in depth next week.
Members of the EU Parliament voted in favor of continuing to move forwards on the EU AI Act. High-risk applications of AI would be regulated under the Act. OpenAI is lobbying for less regulation in the EU, claiming that ChatGPT should not be considered a high-risk application.
Last October, the United States banned the sale of certain high-end computer chips to Chinese individuals, companies, and governments. Yet they did not ban American cloud compute providers from renting out American chips to Chinese purchasers. A white paper from CSET and an op-ed in Foreign Policy both consider this potential policy move.
Tesla’s Autopilot has been involved in 736 car crashes and 17 fatalities. The company claims that their cars crash five times less often than human drivers per mile driven, but has not released data that publicly substantiates that claim.
Microsoft, Meta, and others agree on guidelines for creating and sharing AI-generated media.
Members of the Conference on Fairness, Accountability, and Transparency released a statement saying they “welcome the growing calls to develop and deploy AI in a manner that protects public interests and fundamental rights.” Read the full statement here.
For another excellent breakdown of various AI risks, check out this new taxonomy.
See also: CAIS website, CAIS twitter, A technical safety research newsletter
Keeping the focus and pressure on the human element is critical. The path from sci-fi to nonfiction runs through us.